Traditional Voice Pipeline vs Speech-to-Speech
Why I am writing about voice pipelines
Over the last couple of months I have been building a voice AI application as an MVP, aimed at online reservations for small and medium sized businesses such as hotels, restaurants, and beauty salons. These companies tend to have fewer resources to handle phone calls, online bookings, and simple Q&A, so they end up spending time on work that pulls them away from their actual business.
My idea was to build a small AI MVP that handles voice reservations, AI marketing, and similar tasks, then keep refining it based on user feedback.
Feature requirements
I started with a divide and conquer approach. The long term vision is a dashboard where a business owner can manage bookings, marketing, and customer relationships in one place, similar to Square.
The first feature I worked on was voice reservation. A customer makes a phone call, and an AI voice assistant answers and books an appointment by referencing Google Calendar. It needs to be low latency and accurate, and because mistakes in a booking are costly, human verification is part of the loop. That combination of constraints made a small model an attractive option.
Architecture
I read through a few papers and articles first. I also wanted to start with minimal resources and protect privacy, so I decided to run a local LLM. After some experimentation I landed on the following architecture.
First, I use Twilio to receive the phone call, and the audio is sent to the backend. In the backend I use Silero VAD to detect the caller's speech accurately, then a Whisper STT model to turn that speech into text.
Because of hardware limitations I use a small local LLM. I chose Qwen2.5 7B Instruct. I compared it against Llama 3.2 with a benchmark test, and Qwen2.5 7B Instruct gave better results.
Finally, the local LLM understands the request and creates the reservation through the Google Calendar API. When the request needs more than the model knows on its own, the LLM works as an agent that reaches out to a database, web search, or code execution before answering.
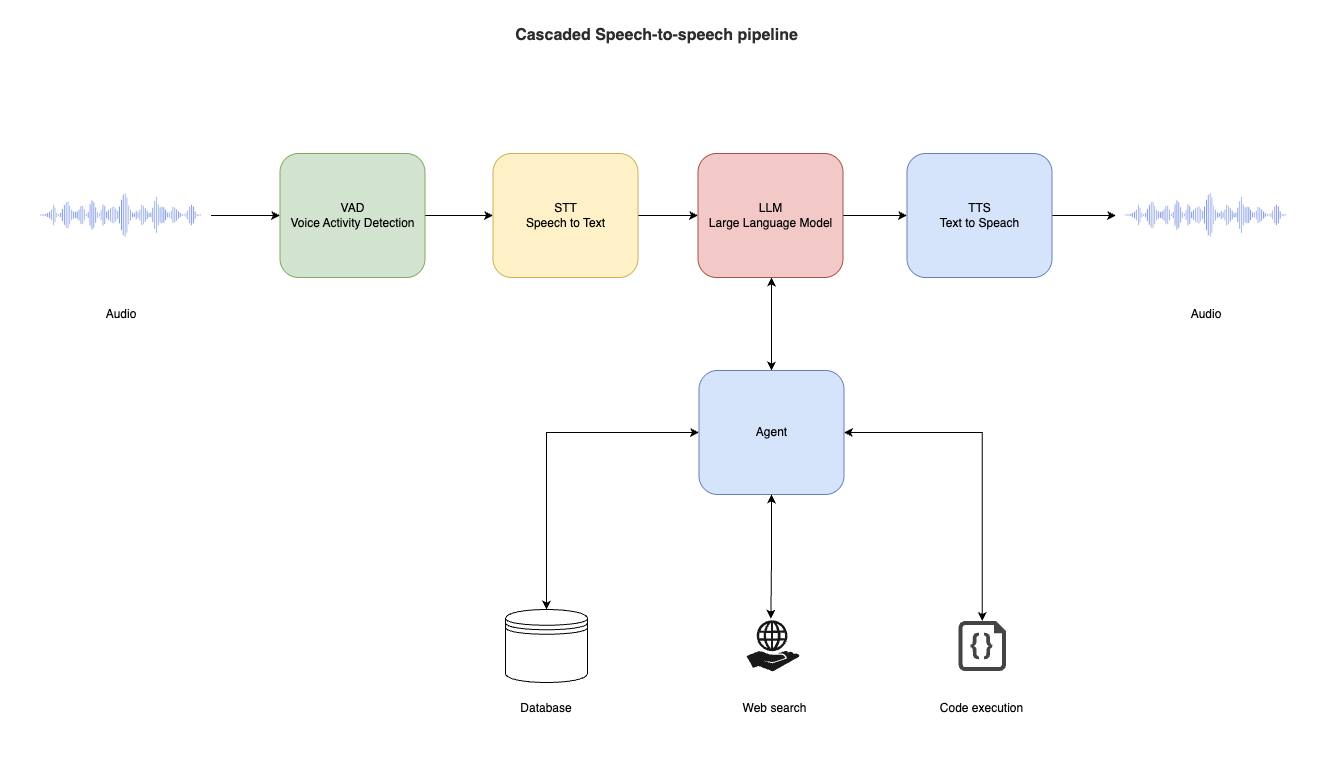
What I found
This architecture works quite well in practice. But I kept thinking that the workflow is not very efficient, because every turn converts speech into text and then text back into speech again.
What if the AI could understand speech and respond with speech directly? That would be more efficient. I searched for this kind of technology and discovered Speech-to-Speech (STS) models. I was surprised. This was exactly what I had been looking for.
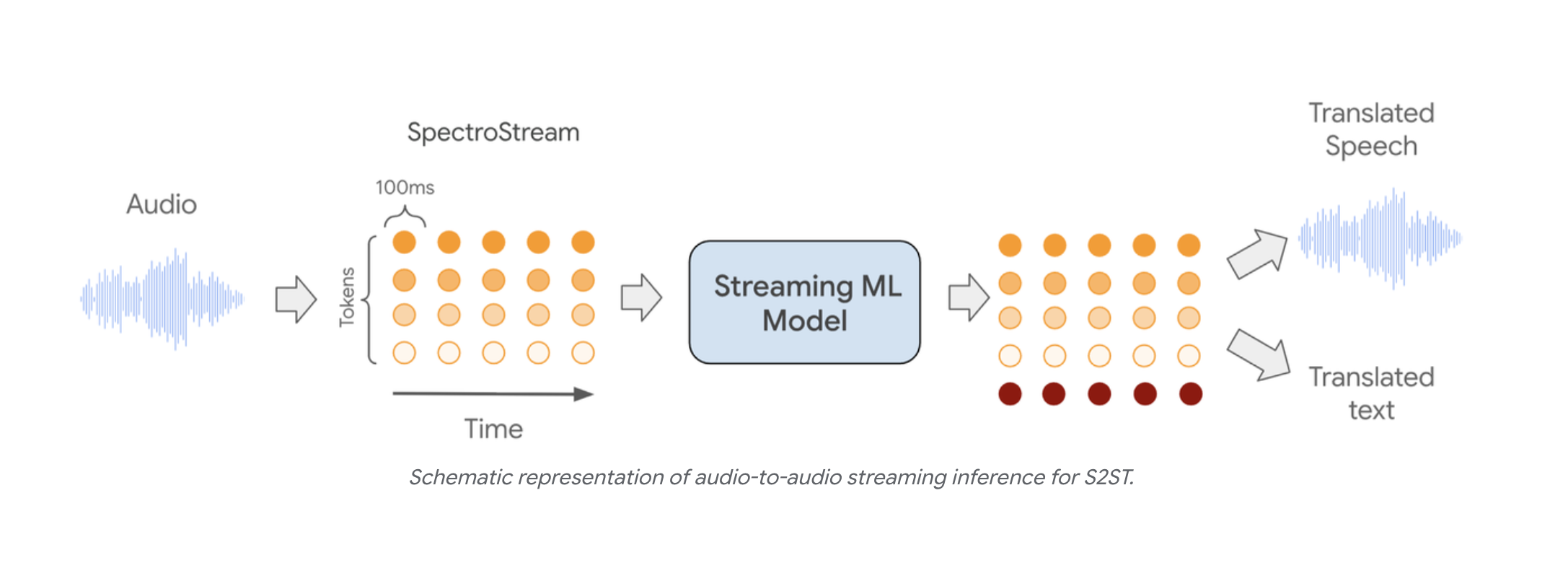 Source: Real-time Speech-to-Speech Translation, Google Research
Source: Real-time Speech-to-Speech Translation, Google Research
In an STS model the audio is tokenized and fed straight into a single streaming model that emits audio (and optionally text) on the other side. There is no separate STT, LLM, and TTS to chain together.
Then I ran into the trade-off. STS models are great for real conversation. They are low latency and need no external round trips, so speed is their strength. But most business applications need a more agentic approach: looking up a source of truth, accessing the latest information, calling external tools. That is where the cascaded pipeline still has the advantage.
Conclusion
My conclusion is that every model has its own characteristics, and to decide which one to use you need to understand both the nature of the model and the actual business case.
Right now every technology comes with trade-offs. My goal is to understand both sides, solve the problems on both sides, and combine the strengths of both so that what I build actually works in the real world.