従来型 Voice Pipeline と Speech-to-Speech
なぜ Voice Pipeline について書くのか
ここ数ヶ月、私はホテルやレストラン、美容室といった中小規模の事業者向けに、オンライン予約を解決するための音声AIアプリケーションをMVPとして開発してきた。こうした事業者は電話対応やオンライン予約、簡単なQAに割けるリソースが少なく、本来の事業から時間を奪われてしまいがちである。
そこで私は、音声予約やAIマーケティングといったタスクを担うAIのMVPをまず作り、ユーザーからのフィードバックを受けながら改善していこうと考えた。
機能要件
まずは分割統治のアプローチで始めることにした。最終的なビジョンは、Squareのように、事業者が予約・マーケティング・顧客管理を一つのダッシュボード上で扱えるようにすることである。
最初に取り組んだのは音声予約機能だ。顧客が電話をかけると、AI音声アシスタントが応答し、Googleカレンダーを参照しながら予約を取る。低レイテンシかつ高精度であることが求められ、予約のミスはコストが大きいため、人による確認をフローに組み込んでいる。こうした制約の組み合わせから、小さいモデルが有力な選択肢になった。
アーキテクチャ
まずはいくつかの論文や記事に目を通した。加えて、少ないリソースで始めたいことと、プライバシーを守りたいという理由から、ローカルLLMを使うことにした。いくつか実験を重ねた結果、次のアーキテクチャに落ち着いた。
まずTwilioで電話を受け取り、その音声データをバックエンドに送る。バックエンドではSilero VADを使ってユーザーの発話を正確に検出し、Whisper STTモデルでテキストに変換する。
ハードウェアの制約から、小さいローカルLLMを使う。私はQwen2.5 7B Instructを選んだ。Llama 3.2とベンチマークテストで比較したところ、Qwen2.5 7B Instructの方が良い結果だった。
最後に、ローカルLLMが要件を理解し、Google Calendar API経由で予約を作成する。モデル単体の知識だけでは足りないリクエストに対しては、LLMがエージェントとして振る舞い、回答する前にデータベースやWeb検索、コード実行といった外部リソースを参照する。
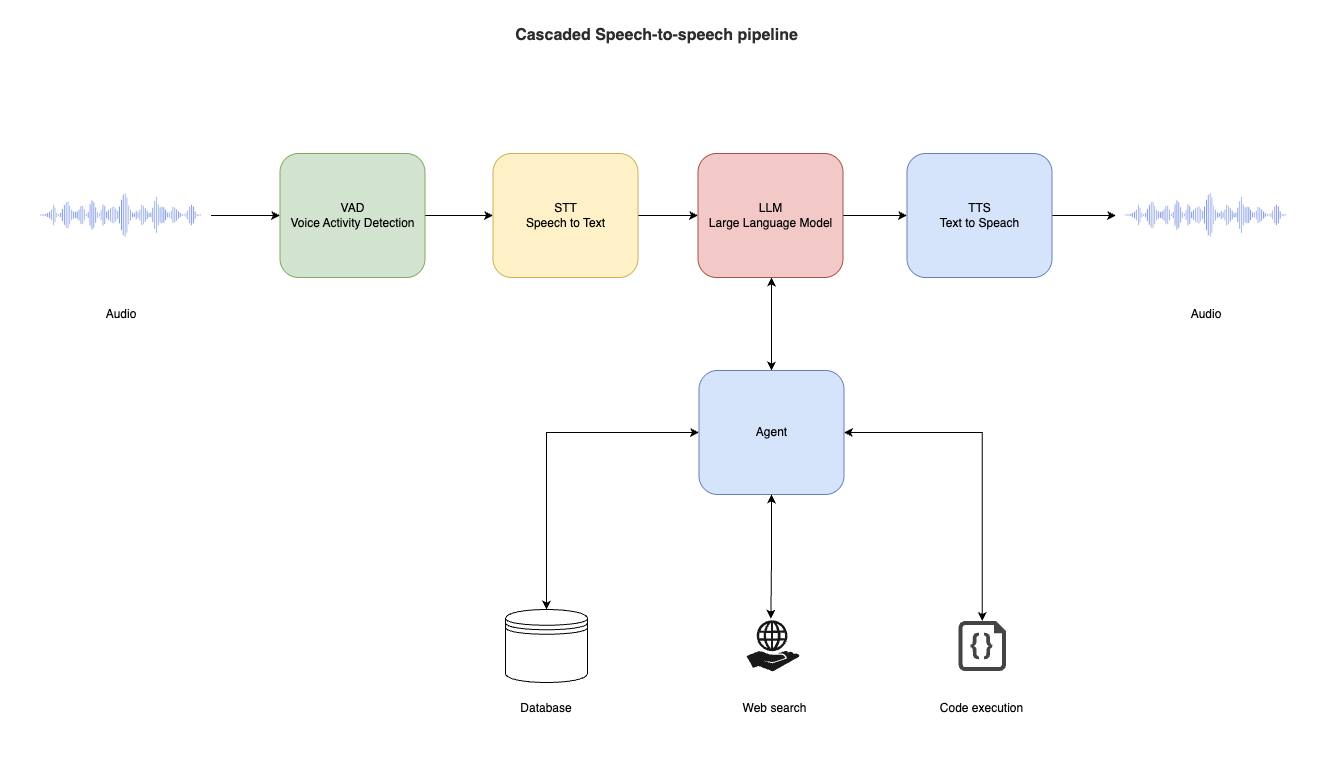
気づいたこと
このアーキテクチャは実際にかなりうまく動く。しかし私は、このワークフローはあまり効率的ではないと感じ続けていた。なぜなら、やり取りのたびに音声をテキストに変換し、またテキストを音声へ戻しているからだ。
もしAIが音声をそのまま理解し、音声で直接応答できたらどうだろう。その方が効率的だ。こうした技術を調べていく中で、Speech-to-Speech(STS)モデルを見つけた。これには驚いた。まさに自分が探していたものだった。
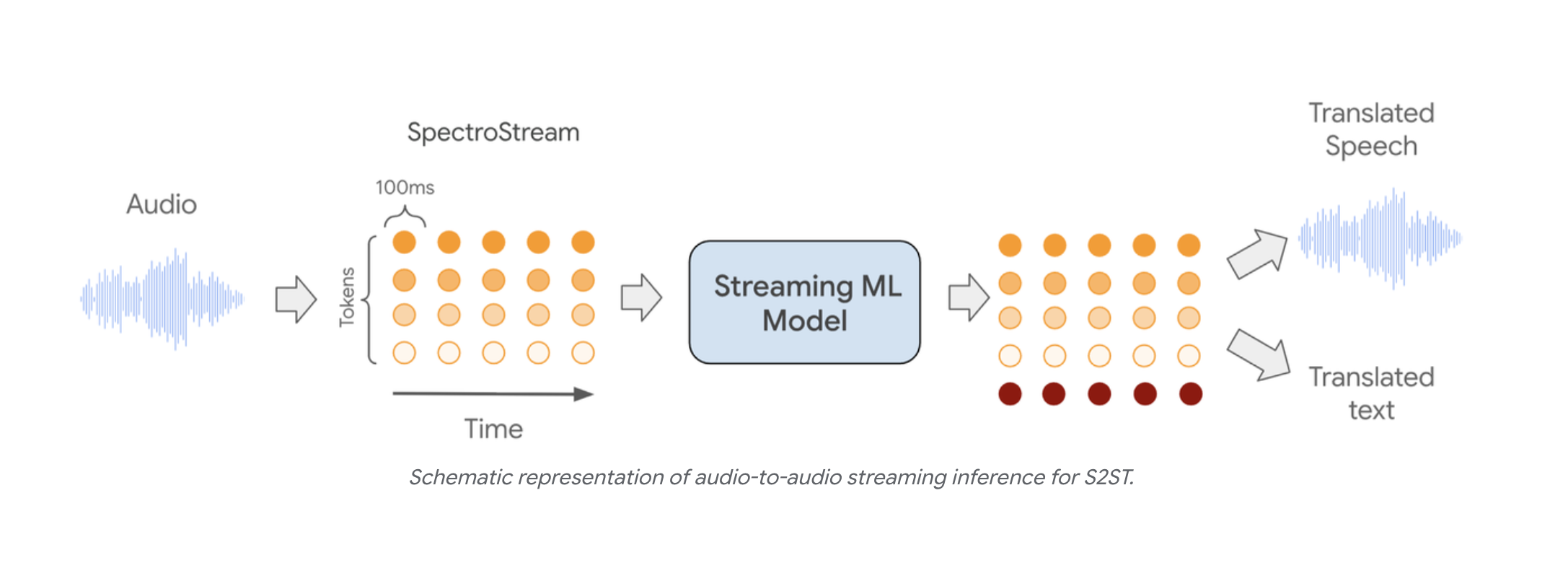 出典: Real-time Speech-to-Speech Translation, Google Research
出典: Real-time Speech-to-Speech Translation, Google Research
STSモデルでは、音声がトークン化され、そのまま一つのストリーミングモデルに入力されて、反対側から音声(必要に応じてテキストも)が出力される。STT・LLM・TTSをつなぎ合わせる必要がない。
ところが、ここでトレードオフにぶつかった。STSモデルはリアルな会話に向いている。低レイテンシで外部への往復も不要なため、スピードが強みだ。しかし、多くのビジネスアプリケーションはより高度なエージェント的アプローチを必要とする。たとえば、根拠となる情報を探したり、最新情報にアクセスしたり、外部ツールを呼び出したりすることだ。この点では、カスケード型のパイプラインに依然として分がある。
結論
私の結論はこうだ。モデルにはそれぞれ特性があり、どれを利用するかを判断するためには、モデル自体の特徴と実際のビジネスケースの両方を理解する必要がある。
現状、あらゆる技術にはトレードオフがある。だからこそ私は、両方を理解し、両方の課題を解決し、両方の利点を活かせるように考え、世の中で本当に役立つものとして実現させていきたい。